

This study was approved by the ethics committee for research involving human subjects of the Keio University Faculty of Pharmacy (Approval No. 240118-2, 240618-1).
Overview
We investigated NLP methods for extracting symptoms and AEs from the clinical texts in the “Subjective” section of pharmaceutical care records documented by community pharmacists. First, we evaluated the performance of an existing general-purpose model designed for Japanese clinical documents using the subjective data. This evaluation was conducted using ground-truth data created based on two annotation guidelines: patient-centric (PCA) and clinician-centric (CCA) annotations (Fig. 1a). Second, we developed a new Named Entity Recognition (NER) model using CCA data and evaluated its performance (Fig. 1b). As an external validation dataset, we assessed the utility of the newly developed model on patient-authored blogs (Fig. 1c).
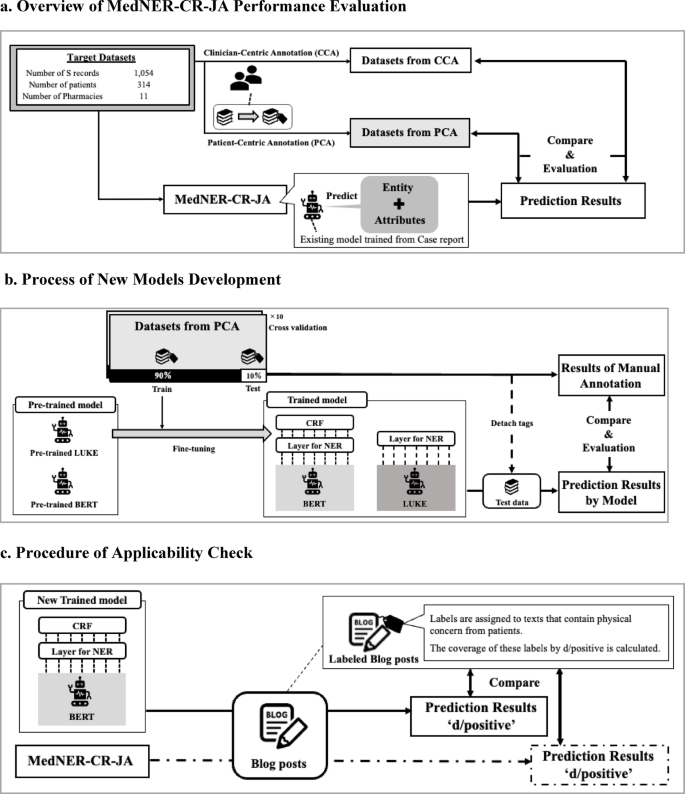
Flow of NLP model construction/evaluation. (a) CCA used an existing guideline modified for pharmaceutical care records, whereas PCA employed a guideline adjusted to align with patient-centered expressions. The model predicts entities corresponding to patient symptoms in the text and their factuality (either positive or negative). These predictions are then compared with the annotation results. (b) The data created under PCA was divided into training and test sets using 10-fold cross-validation, and the pre-trained BERT and LUKE models were fine-tuned. The average performance on the test data was used to evaluate model performance. (c) The applicability of the newly developed model was evaluated by comparing its predictions of actual symptoms with those of an existing model on patient-authored blogs.
Data collection
Pharmaceutical care records
A total of 2,180,902 pharmaceutical care records of 291,150 patients created at Nakajima Pharmacy, a community pharmacy network primarily based in Hokkaido, Japan, between April 1, 2020, and December 31, 2021, were reviewed. The analysis focused on “Subjective” records, which contain patient statements. To enrich the dataset with records likely to contain AE descriptions, we targeted patients who had been prescribed at least one anticancer drug. Filtering was conducted based on YJ codes, which are standardized drug classification codes used in Japan. Specifically, we extracted records containing drugs with YJ codes beginning with “42,” which correspond to anticancer drugs.
To focus on patient-reported complaints, we extracted only the “Subjective” sections of the records, excluding other sections such as “Objective,” “Assessment,” and “Plan.” Subsequently, to ensure feasibility for manual annotation, we limited the dataset to a recent 3-month period (October to December 2020). Among the 50 pharmacies that dispensed anticancer drugs during this period, we stratified the facilities by size and randomly selected records from 11 pharmacies. In total, 1054 records were randomly selected, corresponding to 314 unique patients. The data extraction flow is summarized in Supplementary Fig. S1 online.
Patient blog articles
Additionally, we evaluated the newly developed model by validating its applicability to patient complaint data from different sources, using blog posts personally written by patients. The data source comprised blog articles collected between March 2008 and November 2014 from the Japanese web community “Life Palette”, a patient support website where users share illness experiences and connect through blogs and community diaries.
Explanation of the existing model and annotation rules
We defined NER as the primary NLP task and manually annotated the dataset using two guidelines. Both annotation approaches focused on the symptom tag indicating symptoms or AEs. This tag was based on the disease tags from MedNER-CR-JA22. MedNER-CR-JA is a pre-trained NER model developed by the Nara Institute of Science and Technology to extract medical entities from Japanese clinical texts. It adopts bidirectional encoder representations from transformers (BERT) and was trained on annotated JA case reports23. The model was designed for medical information extraction and supports various tags, including symptoms, drug names, dosages, and anatomical locations, each with detailed attribute types (see Supplemental Table S1). This study specifically focused on disease tags to evaluate model applicability in identifying AE-related expressions in patient complaints. This model can also perform detailed positive or negative classification of symptom expressions.
The first annotation method used was the CCA, which follows conventional NER guidelines for clinical notes24, adjusting annotations to align with the expected MedNER-CR-JA outputs22. We added a detailed description of the CCA guideline in the Supplemental Information (Sect. 1), including tag definitions and special cases derived from annotator discussions. For example, entities such as “no change in symptoms,” colloquial expressions such as “not sleeping well,” and medication-controlled phrases (e.g., “constipation is fine with Lubiprostone”) are treated according to specific rules. Ambiguity in expressions or the presence of metaphorical phrases is also addressed systematically.
The second method, PCA, focuses on patient expressions relevant to AE monitoring and is designed for subjective records. Consequently, a custom guideline was developed (see Supplemental Information Sect. 2). As with CCA, this PCA guideline includes tag definitions and itemized special instructions based on annotator discussions. It defines symptom-tagging rules for both medical and colloquial expressions and includes logic for assigning attributes (positive, negative, suspicious, etc.) to laboratory values, drug references, and temporal language. Examples are provided for difficult cases, such as vague statements, symptom control, and phrases involving the past tense or metaphor. Furthermore, for detailed error analyses, symptoms tagged with the symptom label were categorized based on the Common Terminology Criteria for Adverse Events (CTCAE) ver.5.0, encompassing categories such as general disorders (e.g, fever, weight gain/loss), psychiatric and neurological disorders and gastrointestinal, hepatic, and renal disorders25 (see Supplemental Table S2).
In both annotation approaches, annotation reliability was assessed using 100 randomly selected texts from the dataset. Three researchers with advanced pharmacological knowledge (S. Y., Y. Y., and K. S.) conducted test annotations and assessed label consistency. Agreement level was measured using the Fleiss κ coefficient, which evaluates the agreement rate among the three annotators26,27. After assessing the agreement, three researchers (S. Y., Y. Y., and K. S.) annotated the entire dataset.
Model development
As shown in Fig. 1b, new NER models were developed using PCA data. These models used pre-trained BERT and language understanding with knowledge-based embedding (LUKE) architectures28. Fine-tuning was conducted using PCA-annotated data to adapt the models to patient complaints, which often contain colloquial and medical terms.
In general, recent large language models, such as BERT and LUKE, are trained in two stages. In the first stage, self-supervised learning is conducted on large corpora, such as Wikipedia, to develop a general language understanding, resulting in a pre-trained model. In the second stage, fine-tuning is performed using a small amount of labeled data to adapt the model to the target task. For this study, we used a pre-trained BERT model from the Inui-Suzuki Laboratory at Tohoku University (cl-tohoku/bert-base-japanese-v3) and the Japanese version of LUKE, developed by Studio Ousia (studio-ousia/luke-japanese-base), which was fine-tuned using data generated through PCA29,30.
For fine-tuning, we added a fully connected layer to the final layer of each model. LUKE only required the addition of a fully connected layer, whereas the output from BERT was fed into the conditional random field (CRF) layer. CRF is a probabilistic model that solves sequence labeling tasks and is widely known to enhance model performance when added to the final layer of BERT in both English and Japanese31,32,33. During preprocessing, the target data were tokenized using each model’s tokenizer and subsequently fed into the pre-trained models with a maximum input length of 512 tokens, which is the model’s input limit. Fine-tuning was conducted using an NVIDIA RTX™ 4500 Ada with the following parameters: cross-entropy loss as the loss function, Softmax as the activation function, a batch size of 32, a learning rate of 10− 4, and 5 epochs.
Performance evaluations and metrics
The models were evaluated as shown in Fig. 2. Model performance was evaluated using two methods: position and exact match. In the position match method, a prediction is considered correct when the tag positions in the text match between the model predictions and the annotated data. Exact match requires both the position and the attribute to match for a prediction to be considered correct. Therefore, in exact matching, evaluation metrics were calculated separately for each attribute. In both methods, performance was assessed in terms of precision, recall, and F1 scores. The calculation methods for these metrics are as follows:
$$Precision = \frac{{True\,Positive}}{{True\,Positive\, + False\,Positive}}$$
$$Recall = \frac{{True\,Positive}}{{True\,Positive\, + False\,Negative}}$$
$$F_{1} \,score = \frac{{2 \times precision \times recall}}{{precision + recall}}$$
In the MedNER-CR-JA evaluation, the correct tags for named entities created in both CCA and PCA were compared with those predicted by MedNER-CR-JA. For the newly created model, the target data were split into 90% training and 10% test data. Subsequently, the named entity extractor was evaluated using 10-fold cross-validation. The evaluation metrics were the same as those previously described and were calculated using the average cross-validation results to assess model performance and compare it with that of the existing model (MedNER-CR-JA).
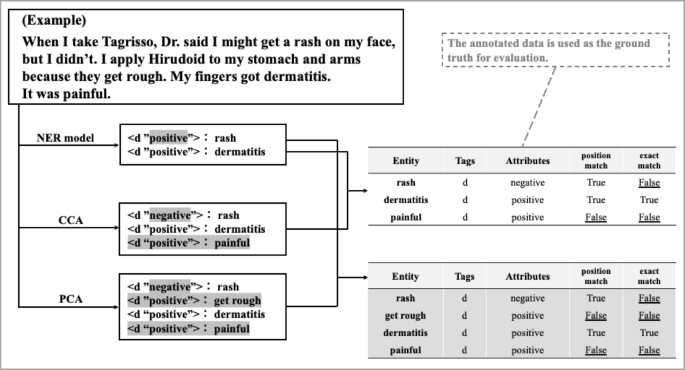
Example of evaluation process. CCA and PCA results were compared with the model outputs. In the position match method, attributes were considered correct even if mismatched, whereas in the exact match method, they were marked as incorrect. CCA, Clinician-centric annotation; PCA, Patient-centric annotation.
Applicability check to other patient narratives
We used patient complaint data obtained from blogs on LifePalette to validate the effectiveness of the newly developed model. For the actual evaluation data, we selected 1,138 entries labeled “Physical” from 2,272 entries previously tagged with five different labels related to complaints of patients with breast cancer in a previous study by Watanabe et al.34. Entries labeled “Physical,” examined from patient perspectives in the PCA of this study, were used to extract physical changes that cause distress in patients with breast cancer. Moreover, this concept largely overlaps with general symptom tags for patients with cancer. In this study, we input a dataset of 2,272 entries on complaints from patients with breast cancer into both MedNER-CR-JA and the newly developed models. Thereafter, we cross-referenced clinical texts assigned a positive symptom tag with those labeled “Physical” to evaluate the ability of the model to extract clinically important AEs from diverse data sources.
link